Crawl Depth: What Is Crawl Depth?
A website’s crawl depth refers to the extent to which a search engine indexes the site’s content. A site with high crawl depth will get a lot more indexed than a site with low crawl depth.

How does Google index a website?
When you Google search something, all that information in the organic search results has to come from somewhere. That somewhere is Google’s index. Think of the index as a massive, expanding library of information. That information takes many forms, too: text, images, videos, documents, you name it.
Search engine crawlers, otherwise known as web spiders, are bots that visit new web pages and store them for the search engine to later index. Crawlers also store any hyperlinks that appear on the pages, and they may visit these linked pages either immediately or later on. Regardless, internal hyperlinks signal to the crawlers that there is more data to store and index.
So, if you create a new page on your site, you can pretty much chill. As long as you link to the new page from other pages on your site, Google’s crawler will eventually follow the link and tell the search engine to index your new stuff.
So, building internal links is an important part of crawl depth. If you don’t have any links, crawlers can’t easily navigate your site, which means less of your content will get indexed and you’ll suffer in the organic search results.
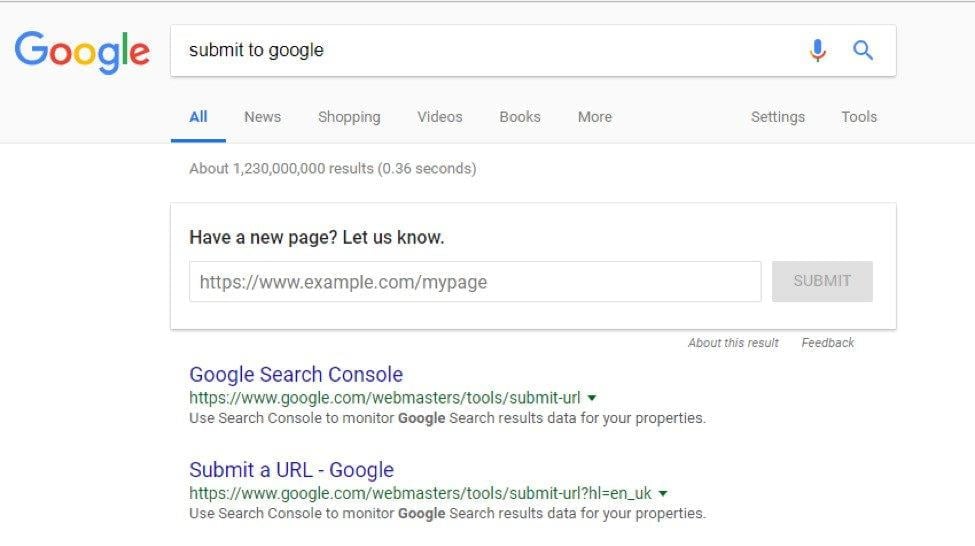
Alternatively, if you want your new page indexed as soon as possible, you can directly submit it to Google. Simply Google search “submit URL to Google” and paste the URL for the new page in the submission field.
How often does Google crawl my website?
Think about how Google models its business: it attracts Internet users so it can sell ad space to advertisers. Without the users, there would be no demand for ad space, and Google would lose essentially all of its revenues.
Therefore, it’s very important that Google keeps its search results up-to-date and relevant. As such, crawl frequency – how often a site gets crawled and indexed – depends largely on the importance of the site. For example, whereas mainstream news outlets are crawled almost constantly, your buddy’s small garage door business gets crawled on occasion.
The speed of your site is also a big factor. If Google is crawling your site, and your site begins to slow down or your server begins to fail, the crawler will do less. You do not want the crawler to do less because that translates to less visibility for your site. Making your site fast and easily navigable is essential to survival in the organic search results.
What can I do?
It’s a good idea to maintain an XML sitemap to provide Google with a directory of the pages it needs to regularly crawl.
Stay on top of redirects and dead 404 pages. A redirect isn’t the end of the world, but it does slow down the crawler. Google will not allocate infinite resources to crawling your site, so it’s best to make it as quick as possible. Dead 404 files are even worse, as they act essentially as roadblocks.
In the same vein, beware duplicate content. Forcing the crawler to visit the same page two, three, or four times is a complete waste of time and resources. It keeps the crawler from visiting new, relevant pages on your site and diminishes your performance in organic results.