Search Engine Spider: What Is a Search Engine Spider?
A search engine spider, also known as a web crawler, is an Internet bot that crawls websites and stores information for the search engine to index.
Think of it this way. When you search something on Google, those pages and pages of results can’t just materialize out of thin air. In fact, they all come from Google’s index, which you can visualize as an enormous, ever-expanding library of information – text, images, documents, and the like. It’s ever-expanding because new web pages are created every single day!
So, how do those new pages get into the index? Search engine spiders, of course.
How do search engine spiders work?
Spiders, such as Googlebot, visit web pages in search of new data to add to the index. This is critical because Google’s business model (attract consumers and sell ad space) is reliant on providing high-quality, relevant, and up-to-date search results.
The spiders are pretty smart, too. They recognize hyperlinks, which they can either follow right away, or take a note of for later crawling. Either way, internal links between pages on the same site function similarly to stepping stones, in that they pave the way for spiders to crawl and store new information.
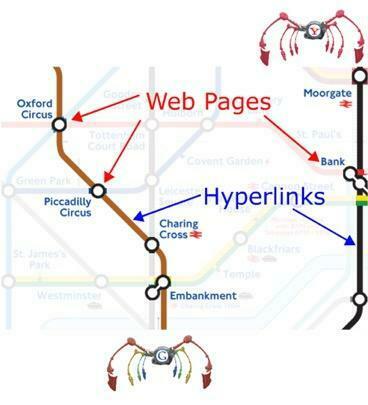
Speaking of which…
Why should I care about search engine spiders?
Search engine optimization (SEO) is all about boosting your visibility in the organic search results. You’re aiming to attain Domain Authority and get your site on page one for as many keywords as possible.
A good first step towards page one: allowing the search engine to actually find your web pages. If your stuff isn’t getting indexed, you’re not even sniffing page 13.
The good news: you don’t have to work too hard to get your new pages crawled and indexed. Basically, as long as you link to your new content from some old content, the spiders will eventually follow those links to the new page and store it for indexation. Like we said earlier: internal links are crucial.
If you’re anxious to get your new stuff indexed and in the search results as soon as possible, you can directly submit the new URL to Google and tell the spider to crawl it. Once you hit submit, it shouldn’t be more than a few minutes.
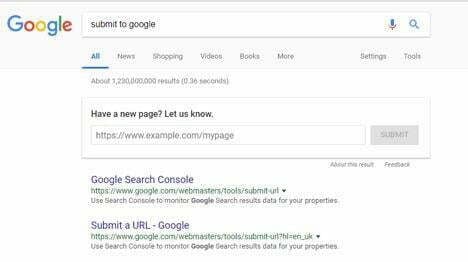
Can I do anything to help the search engine spiders?
Why, yes. Yes, you can.
In essence, you want the spiders to see as much of your site as possible, and you want to make their navigation as seamless as it can be. Start with your site speed. The spiders aim to work as quickly as possible without slowing down your site at the expense of user experience. If your site starts to lag, or server errors emerge, the spiders will crawl less.
This, of course, is the opposite of what you want: less crawling means less indexing means worse performance in the search results. Site speed is key.
Maintain an XML sitemap to create a convenient directory for the search engines. This will tell them which URLs need regular crawling.
A basic principle of site architecture: keep clicks to a minimum. To be more precise, no page on your site should be more than 3 or 4 clicks away from another. Anything more than that makes navigation cumbersome for users and spiders alike.
Finally, reserve a unique URL for every single piece of content. If you assign several URLs to the same page, it becomes unclear to the spiders which they should use. Remember: a fundamental part of SEO is making the spiders’ jobs easy. Don’t belabor the spiders, and you’ll be just fine.