Apologies for the (slightly) misleading headline on dofollow links. You won’t find something like this within this article. What you will find is a means for accumulating passive, recurring, and authoritative links to content by leveraging the popularity and search prominence of Wikipedia (which I assume probably sounds pretty good, too).
Wikipedia is Where Research is Being Done
There are a number of bloggers, journalists, students, and others in control of Web content who rely on some combination of Google and Wikipedia to research a topic. This can be evidenced by a couple of handy graphs.
Lots of people visit Wikipedia, Compete puts the estimate at somewhere around 60+ million a month.
Many of these visitors link at Wikipedia:
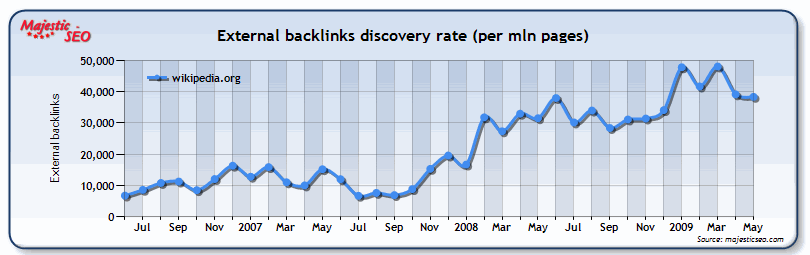
But that in and of itself may not be terribly interesting to us, because Wikipedia no follows external links, so getting your link included on a Wikipedia page likely offers little direct ranking advantage for your site.
Often times, however, people doing research will link beyond the Wikipedia article itself to a properly placed resource they’ve discovered within a Wikipedia article. And some topics are very frequently researched, and very freqently linked at.
This offers you a very leveraged means of “pitching” your content to a wide variety of people who are actively researching the subject matter.
The Nuts & Bolts: Four Steps to Making this Strategy Work For You
An important thing to note about this tactic is that not unlike many quality link building efforts: it requires a certain amount of time and resources, and carries with it the risk of relative or abject failure from a link acquisition perspective. For this reason “doing your research” is crucial. Here are four steps to making Wikipedia work for you as a link building tactic:
Step 1: Define a Short But Broad Query Set
The first step in the process is to determine the appropriate topic page for your link. This comes before actually writing the content, because ultimately your content should be tailored to the audience you’re trying to reach, which we’ll talk about in greater depth in step three.
Here, we simply want to do a bit of preliminary keyword research. First we want to pull together a quick list of broad keywords that relate to our subject. We can do this by leveraging resources such as the Google Keyword Tool, a WordStream profile, or any number of other sources. If you’re struggling to come up with a list of related keywords for your subject, you definitely want to circle back and invest more time in learning about keyword research and information architecture. We have some good resources here on the site, and an SEO Book Training membership is always a good investment.
Next you want to cull that list some so that you’re left with 20-50 phrases that represent topics you can create a very strong resource for.
For instance, if you were attempting to leverage this strategy for a site dealing with legal topics, you might have started with a variety of high traffic keywords but realize that “legal debt advice” isn’t a good one because you aren’t well-versed in that area of law. As you create your final list ask yourself:
- Is this a popular query/topic?
- Is this relevant to my site, business, and my company’s knowledge base?
- Can we write an authoritative article on this topic?
Step 2: Identify Heavily Trafficked Pages Where Wikipedia Ranks
Once you have a nice set of target queries, you need to identify which of these queries will sync up with a high-traffic Wikipedia page that ranks for a term that you could create a resource for. There are a couple of great tools to use for this purpose.
The first tool is SEM Rush. SEM Rush is a great tool for unearthing competitive insights. In this case we want to take a look at the Wikipedia.org domain to see which words it ranks for organically:
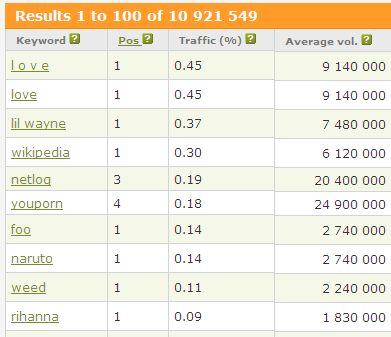
Obviously this list isn’t particularly useful for our law blog, but the image above gives you a good idea of the type of data you can get with SEM Rush. You can quickly learn:
- Where a Wikipedia page ranks
- The percentage of traffic it generates for that keyword
- The amount of traffic the query drives
The second two metrics are definitely estimates, but they give you a good base line for determining the most popular articles, and roughly how much traffic that Wikipedia page generates. What you want to do next is export this list of keywords returned by SEM Rush (NOTE: for this step, to get beyond the top ten most popular keywords, you’ll need an SEM Rush subscription. They’re relatively cheap; personally I use the white labeled version of the tool which is available with an SEO Book Training Membership. Read more about the SEO Book version of the tool here).
Once you have an Excel dump of this data (SEM Rush reports thousands of pages of query data for Wikipedia), you want to sift through that data and identify terms related to yours. The easiest way to do this is probably to sign up for a free trial of WordStream, dump the data into our tool, and query the database for some of your terms:
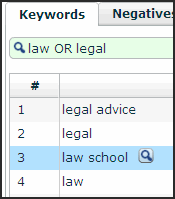
Here we see that WordStream is returning all of the results that contain law or legal from our list. This lets us get a quick view of the data that pertains to our site.
You could also sift through this particular data set in Excel pretty easily (if you’re not an Excel wiz check out Josh Dreller’s series on excelling at Excel; it’s outstanding and really detailed).
From here, we’ll want to take a look at the Wikipedia page or pages that seem the most interesting. We can navigate to the page and take a look at the other types of resources being cited there. Make sure you can create a piece of content that will make sense within the context of the Wikipedia page, preferably filling a hole they don’t already have.
Finally, it’s a good idea to double check to make sure the page is actually driving something approaching the amount of traffic SEM Rush predicted. You can do this by taking a look at the publicly available traffic data for this Wikipedia page:
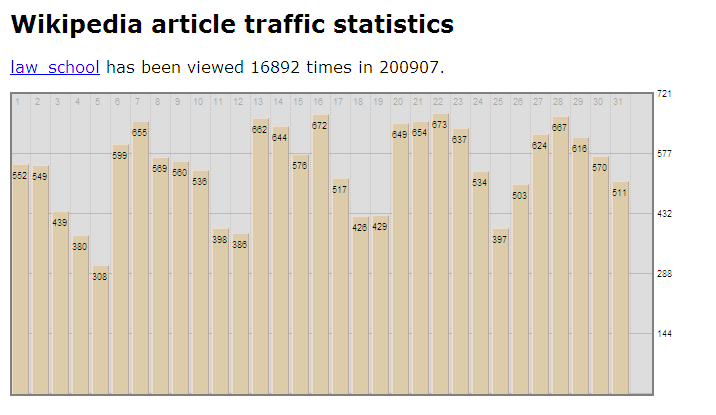
Here we see that this page alone is driving around 17,000 visits a month.
Step 3: Create a Resource on the Topic
Now that you’ve targeted a specific page to acquire a link on, you just need to write a really authoritative piece on the topic (easy enough right?). A good way to go about doing this is to look at the resources already linked to on the page you are trying to get a link from. Think about how to craft something similar, but which speaks to something missing on the page in question.
Step 4: Insert the Link on the Target Wikipedia Page
Finally, you need to actually go and inject the link onto the page. Really this can be an art form in it’s own right. The quick and dirty way to do this is to assess the character of the page and try to find the right spot for your link, in addition you might consider:
- Viewing the page discussion
- Viewing the page history
- Looking for sites similar to yours that have Wikipedia listings for similar topics
For more info on the mechanics of getting a link on Wikipedia you can check out:
- Dosh Dosh’s guide to getting listed in Wikipedia (a bit old but much of it seems to still apply)
- SEO Moz’s article on Wikipedia (again an older one, apparently I’m the only person in online marketing still writing about Wikipedia)
- AND finally a favorite article of mine on pushing past Wikipedia in the SERPs, because I couldn’t find a third useful Wikipedia how-to plug in here
The best part about this is that even if your link gets rejected by Wikipedia, you’ll have crafted a really high quality resource that you know people are looking for (so please don’t come yell at me if you run through the four steps and an overzealous Wiki editor nukes your link :)).
The Larger Story Here
The above outlines a way you can leverage Wikipedia to gain some really high quality back links. Ultimately the aim of “link building” and “link baiting” should be to get citations from high quality sites; writing things like Wikipedia or Twitter off as tools that can help you build links simply because they started slapping the no follow tag on external links is like saying you shouldn’t use Email to contact possible link prospects because all of the stuff you’re writing back and forth doesn’t get indexed by Google.
Look at link building as a larger, wholistic, natural process that has a variety of inputs and outputs. Expecting every single activity you do to immediately bear link fruit is a great way to ignore a ton of high-powered link building strategies.
Are you wasting money in Google Ads?

Meet The Author
Tom Demers
Tom Demers is Co-Founder & Managing Partner at Measured SEM and Cornerstone Content.